PyTorch, Pytorch-lightning을 이용해서 프로젝트를 진행하고 있는데
자주 쓸 것 같지만 정리해두지 않으면 까먹을 것 같은 트릭들의 모음
Learning rate관리는 training task의 핵심 중 하나이다. 특히 Pre-training task를 진행할 땐, learning rate를 잘 관리해주지 않으면 모델이 제대로 수렴되지 않는다. 이번 포스트에서는 다음 두개를 집중해서 정리한다.
- Learning rate scheduler
- Learning rate monitor
Learning rate scheduler
torch.optim.lr_scheduler 내에는 간편하게 사용할 수 있는 scheduler class들이 정의되어 있다.
Pytorch 공식 documentation here 에서 확인할 수 있고
나는 이 블로그 here를 많이 참고했었었다.
자세한 Learning rate scheduler들은 위 링크에 잘 정리되어있으니 넘어가도록 한다.
InverseSqrtScheduler
나는 이번 프로젝트에서 facebook research팀이 ESM model을 training할 때 사용한 Inverse Square Root with Warmup scheduler를 구현해서 썼다. (fairseq github)의 구현을 참고해서 작성했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from torch.optim.lr_scheduler import LambdaLR
class InverseSqrtScheduler(LambdaLR):
""" Linear warmup and then follows an inverse square root decay schedule
Linearly increases learning rate schedule from 0 to 1 over `warmup_steps` training steps.
Afterward, learning rate follows an inverse square root decay schedule.
"""
def __init__(self, optimizer, warmup_steps, last_epoch=-1):
def lr_lambda(step):
if step < warmup_steps:
return float(step) / float(max(1.0, warmup_steps))
decay_factor = warmup_steps ** 0.5
return decay_factor * step ** -0.5
super(InverseSqrtScheduler, self).__init__(optimizer, lr_lambda, last_epoch=last_epoch)
Lambda scheduler를 사용할 때, lambda 함수는 정확한 learning rate를 반환하는게 아닌
maximum learning rate에 곱해질 factor (0 ~ 1) 값을 반환해주면 된다
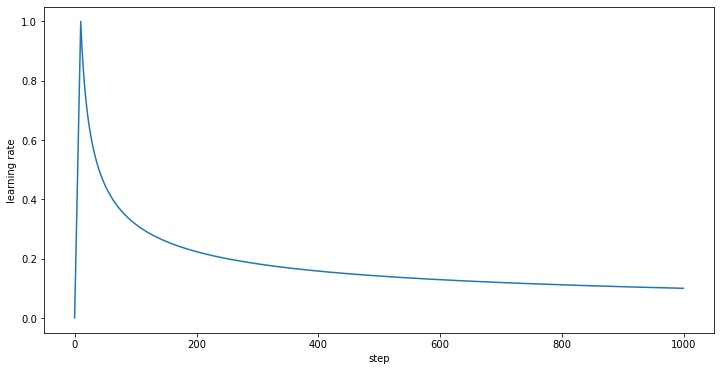
이 scheduler를 사용하면 다음과 같은 형태로 learning rate가 관리된다.
configure_optimizers()
이렇게 만든 scheduler를 pytorch-lightning에서 사용하는 것은 아주 간단하다. configure_optimizers() 함수 내에서 다음처럼 써주기만 하면 된다.
1
2
3
4
5
def configure_optimizers():
optimizer = AdamW( ... )
scheduler = InverseSqrtScheduler(optimizer, self.hparams.warmup_steps)
return [optimizer], [scheduler]
그런데 한가지 주의해야할 사항이 있다. 위와같이 사용하면 learning rate가 epoch 단위로 관리되는 것이다. fine-tuning등 일반적인 training task에서는 굳이 learning rate를 step단위로 관리할 필요가 없지만, masked language model 이나 GAN과 같은 모델에서는 이야기가 다르다. 한 epoch가 굉장히 길기 때문에, step단위로 learning rate을 조절해 줄 필요가 있다. (굉장히 쉬운 테크닉인데, 검색해도 잘 나오지 않아서 하루종일 헤맸다 ㅠㅠ)
1
2
3
4
5
6
7
8
9
def configure_optimizers():
optimizer = AdamW( ... )
scheduler = InverseSqrtScheduler(optimizer, self.hparams.warmup_steps)
sch_config = {
"scheduler": scheduler,
"interval": "step",
}
return [optimizer], [sch_config]
아주 작은 수정인데, interval을 step으로 설정해주면 scheduler의 step()함수가 매 epoch대신 매 step마다 호출된다. return [optimizer], [sch_config] 대신 다음과 같이 써도 괜찮다.
1
2
3
4
return {
"optimizer": optimizer,
"lr_scheduler": sch_config,
}
Learning rate monitor
log()
Learning rate가 잘 변하고 있는지 지켜보고 싶은 심정은 모두 똑같을 것이다. learning rate를 확인하는 직관적인 방법은 다음처럼 할 수 있다. training_step() 또는 validation_step()에서 log를 찍는 것이다.
1
2
3
4
5
6
7
8
def training_step():
scheduler = self.lr_schedulers()
loss = self.model(**batch).loss
self.log('train_loss', loss, on_epoch=True)
self.log('learning rate', scheduler.get_lr()[0], on_epoch=True)
return loss
Callback
그런데 pytorch-lightning을 쓰는 이유 중 하나는 불필요한 코드들을 간단하게 정리하기 위함이 아닌가!! 저렇게 주저리주저리 코드를 다는 대신, 이미 구현되어있는 Callback을 가져다쓰는 편한 방법이 있다.
1
2
3
4
5
6
7
8
9
import pytorch_lightning as pl
from pytorch_lightning.callbacks import LearningRateMonitor
lr_monitor = LearningRateMonitor(logging_interval='step')
trainer = pl.Trainer(
...
callbacks = [lr_monitor],
...
)
Scheduler Name
LearningRateMonitor를 이용해 모니터링한 값은 tensorboard를 이용해 확인할 수 있다. 기본적으로 optimizer의 이름으로 표시되며, 특별한 이름을 부여하고 싶다면 다음처럼 scheduler를 수정해주면 된다.
1
2
3
4
5
6
7
8
9
10
def config_optimizers():
optimizer = AdamW( ... )
scheduler = InverseSqrtScheduler(optimizer, self.hparams.warmup_steps)
sch_config = {
"scheduler": scheduler,
"interval": "step",
"name": "my_little_scheduler",
}
return [optimizer], [sch_config]